СТАТИСТИЧЕСКИЙ ПОДХОД
К ИССЛЕДОВАНИЮ ПЛАНА СОДЕРЖАНИЯ
ХУДОЖЕСТВЕННОГО ТЕКСТА*
Современные исследования по статистике речи, при всем многообразии рассматриваемых в них вопросов и используемого материала, как нам кажется, развиваются по двум главным направлениям.
Для одного из них характерно все большее усложнение используемого статистического аппарата, а как следствие этого — все более строгий подход к получаемым эмпирическим данным. Работы такого рода все более сближаются с другими областями приложения математической статистики, их объект — язык — оказывается в одном ряду с другими объектами статистического исследования.
Несомненно, данное направление очень важно, так как способствует расширению исследовательского аппарата лингвостатистики. Однако более относящимся к компетенции этой дисциплины как части лингвистики представляется второе направление, оперирующее, как правило, значительно более скромным математическим аппаратом (и потому получающее зачастую менее строгие результаты) и акцентирующее свое внимание на получении некоторых содержательных (с точки зрения собственно лингвиста) выводов. Такими работами можно считать исследования по формализации отношений плана содержания языка1, соотнесению получаемых данных с некоторыми компонентами психолингвистической модели.
Несомненно, математическая строгость и лингвистическая значимость получаемых выводов не составляют неизбежной альтернативы. Более того, оба отмеченных направления глубоко родственны прежде всего в том, что оба они противопоставляют себя тому примитивному счету, не простиравшемуся дальше самых примитивных арифметических операций и предельно тривиальных, лежащих на поверхности выводов, который был характерен для лингвостатистики первоначально. Однако в преодолении данного состояния указанные направления шли несколько различными путями: с одной стороны — замена элементарных арифметических операций серьезным статистическим анализом, с другой — переход от столь же примитивных рассуждений об «употребительности» тех или иных групп слов (смысловых или грамматических) к поиску таких, не лежащих на поверхности, категорий, осмысление при помощи которых позволило бы получить серьезные и интересные для лингвиста (хотя и не обязательно вполне строгие с точки зрения статистика) результаты.
Все сказанное до сих пор о лингвостатистике может быть отнесено и к работам, посвященным статистическому изучению вторичных моделирующих систем, с той лишь оговоркой, что здесь значение второго подхода возрастает — по очень простой причине. Дело в том, что такие работы оперируют, как правило, значительно меньшим объемом выборки. Если для лингвистического частотного словаря минимальным объемом выборки для получения разумных (с точки зрения достоверности) результатов обычно признается 200 тысяч словоупотреблений, причем имеются словари-гиганты2, могущие служить надежной базой при различных сопоставлениях, то объем поэтических частотных словарей по необходимости оказывается во много раз меньше. Естественно, что достоверность получаемых данных также оказывается недопустимо низкой. С точки зрения собственно статистической, этими данными невозможно оперировать.
Известно, в частности, что с уменьшением частоты слова в списке возрастает относительная ошибка, то есть возможное отклонение эмпирически полученного значения частоты в рассмотренной выборке от истинной вероятности слова в генеральной совокупности текстов. Величина относительной ошибки (δ) 33 %, считающаяся в лингвистике предельно допустимой (и, конечно, достаточно большая сама по себе), оказывается у слов с частотой F равной 35. Меньшие значения частот дают ошибку, превышающую указанный предел, и тем самым признаются недостаточно достоверными. Так, у слова с частотой 10 величина относительной ошибки (δ) составляет 61 %, у слова с частотой 4 — δ = 98 %. Это значит, что область, в которой возможны колебания частот таких слов, составит 4 ≤ F ≤ 16 в первом случае и 0 ≤ F ≤ 8 — во втором. Понятно, что для «малого» словаря с ничтожным удельным весом слов, частота которых превышает указанный порог, получаемые данные носят сугубо приблизительный характер.
Но трудность состоит не только в объеме выборки самом по себе, а и в том, что, если для лингвистического анализа низкочастотные слова действительно не имеют существенного значения и могут рассматриваться лишь очень общо, для исследователя поэтического словаря такие слова зачастую представляют большой интерес и должны рассматриваться весьма дифференцированно. Следовательно, даже значительное увеличение объема выборки (в тех случаях, где оно окажется возможным) не решит указанной проблемы — необходимости иметь постоянно дело с низкочастотными единицами, а следовательно, и с заведомо недостоверными показателями3.
Правда, надо заметить, что от языка одного автора (тем более — в произведениях одного жанра) можно ожидать большей «компактности», а следовательно, меньшей неопределенности, меньших возможностей варьирования получаемых данных, чем в том случае, когда мы обращаемся к исследованию некоторого стиля и в особенности — языка в целом. Но степень возможного уменьшения неопределенности в этом случае совершенно неизвестна, к тому же она может быть различной для разных авторов и жанров; поэтому рассчитывать на это не представляется возможным.
Все сказанное отнюдь не имело целью дискредитировать идею применения статистических методов в исследовании вторичных моделирующих систем, а было необходимо лишь для того, чтобы иметь возможность поставить вопрос об истинном назначении этих методов (применительно к избранному объекту) и результатах, которые можно от них ожидать. Нам хотелось рассеять достаточно широко распространенное предубеждение, заставляющее видеть в статистических данных «точную» картину, противополагаемую «приблизительным» интуитивным определениям. Если это и верно для областей, опирающихся на достаточно большой (в статистическом смысле) материал, то в нашей области, в условиях малых выборок и больших допусков относительных ошибок, такое противопоставление выглядит сомнительным: размах колебаний здесь оказывается немногим отличающимся от неопределенности чисто интуитивного анализа.
Для иллюстрации данного положения приведем такой пример. Р. М. Фрумкина и А. П. Василевич, сопоставляя интуитивную оценку частоты слов со списком, полученным Э. Штейнфельдт на основе обследования 400 тысяч словоупотреблений4, приходят к выводу, что наименьшая разница между логарифмами частот слов этого списка должна составлять 0,75 (lg F1 — lg F2 ≥ 0,075), чтобы различие частотной характеристики этих слов надежно фиксировалось интуицией говорящих5. Иначе говоря, для достоверного суждения (на основе интуиции) о том, что F1 > F2, необходимо, чтобы соотношение этих частот удовлетворяло следующему условию:
lg F1 — lg F2 ≥ 0,075 или
 | (1) |
Вспомним теперь, что для утверждения о том, что слово i1, имеющее в частотном списке частоту F1, действительно более употребительно, чем слово i2 (с частотой F2), необходимо, чтобы выполнялось следующее условие:
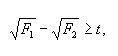 | (2) |
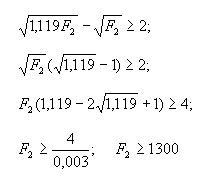 |
Это значит, что величина F2 ≈ 1300 — это нижний порог в частотном списке, ограничивающий зону, в пределах которой мы (с надежностью в 96 %) можем утверждать, что при соотношении частот = 1,12 слово i1 более употребительно в языке, чем i2, — то есть делать утверждения, равные по силе интуитивному определению различия употребительности. Для меньших частот аналогичное соотношение ![]() не позволит нам сделать аналогичный вывод с достаточной степенью достоверности. Так, уже для F2 = 1000 (F1 = 1120) t = 1,85, то есть позволяет делать наше утверждение с надежностью в 92 %; для F2 = 100 (F1 = 112) t = 0,58 (≈ 40 % надежности) и т. д.
не позволит нам сделать аналогичный вывод с достаточной степенью достоверности. Так, уже для F2 = 1000 (F1 = 1120) t = 1,85, то есть позволяет делать наше утверждение с надежностью в 92 %; для F2 = 100 (F1 = 112) t = 0,58 (≈ 40 % надежности) и т. д.
В словаре Штейнфельдт указанная выше зона охватывает всего 31 слово. Таким образом, теоретически возможные колебания, которые необходимо учитывать при интерпретации фактов, полученных на основе частотного списка, в подавляющем большинстве случаев оказываются едва ли не большими, чем колебания при чисто интуитивных определениях7.
Но если надежды на повышение точности результатов с помощью статистических методов оказываются неосновательными, то в чем же состоит назначение данных методов при изучении знаковых систем? Нам кажется, что на этот вопрос легче ответить, освободившись от гипнотического воздействия несложных арифметических операций, якобы способных явить нам точную картину исследуемого объекта. Мы должны исходить при этом из того (простого, в сущности) рассуждения, что частотное распределение единиц языка в речи — это компонент формальной характеристики данных единиц, такой же, как их внутренняя структура, строение парадигмы, характер сочетаемости с другими единицами. Подобно этим последним критериям (уже хорошо «освоенным» наукой), частота встречаемости единицы в тексте является одним из ее формальных показателей, с помощью которых передаются некоторые категории плана содержания. Задача, следовательно, состоит в том, чтобы установить связь между некоторыми определенными компонентами вероятностной характеристики исследуемой языковой единицы (в нашем случае — слова) и соответствующими компонентами ее содержательной характеристики и тем самым формализовать эти последние. «Точность» такого анализа едва ли может превышать точность формального описания знаковых систем с помощью других известных нам критериев (например, дистрибутивного). Но при этом естественно ожидать, что введение нового формального критерия позволит показать в структуре языка некоторые компоненты, которые до сих пор были формально непредставимы. Если это ожидание сбудется в дальнейшем, можно предполагать, что данные методы ждет такая же судьба, как и методы дистрибутивного анализа, которые едва ли сделали лингвистику более точной наукой, но существенно расширили возможности формального представления языковой структуры.
Итак, не следует ожидать, что использование статистических данных приведет к замене описаний, характеризуемых известной степенью неопределенности, допущением некоторых переходных областей, неясно обозначенными границами между классами, — описанием строго дискретным, оперирующим только жесткими определениями и классификациями. Однако мы вправе надеяться, что исследование количественных отношений в тексте обогатит возможности моделирования языковой структуры — в частности, ее плана содержания.
Приведем пример того, как чисто количественная модель распределения лексики в художественном тексте оказывается имеющей отношение к значению — моделью содержания. Правда, пример этот (для простоты, о чем будет сказано ниже) взят не из области частотных словарей. Однако, как и в частотных словарях, речь здесь пойдет о значении частотных количественных показателей.
В рассказе Л. Н. Толстого «Три смерти» текст, согласно названию, отчетливо делится на три части: смерть «госпожи», смерть ямщика и смерть дерева. Части эти не только противопоставлены на уровне содержания, но и имеют подчеркнуто различную величину. Описанию смерти «госпожи» посвящены главы I и III, смерти ямщика — глава II, смерти дерева — часть главы IV (со слов «Ранним утром, чуть зорька…»). В первой из выделенных нами частей 2361 словоупотреблений, во второй — 849, в третьей — 2798. Соотношение частей (с точностью до 1 — 9:3:1) позволяет, в рамках текста как целого, охарактеризовать смерть «госпожи» как описанную подробно («многими словами»), смерть ямщика как изображенную менее подробно («меньшим количеством слов») и смерть дерева как обрисованную весьма лаконично («наименьшим количеством слов»). Но три смерти — это смерть трех персонажей, каждый из которых, вместе с его окружением, составляет особый мир, противопоставленный каждому из двух остальных в социальном, философском, этическом, ценностном и других планах. В рассказе отчетливо намечена стройная система оппозиций, носящих в основном трехступенчатый градуальный характер9.
| I | II | III |
| 1. дворянский мир | народный мир | природный мир |
| 2. мир ярко выраженной личности |
мир слабо выраженной личности |
мир невыраженной лич- ности |
| 3. мысли о жизни, боязнь смерти (суетность) |
мысли о душе, небоязнь смерти (несуетность) |
мир вне сознания и мысли |
| 4. смерть, тяжелая для окружающих (эгоис- тическая) |
смерть, не обременитель- ная для окружающих (не- эгоистическая) |
смерть, незаметная для природного окружения персонажа (вне оппози- ции «эгоизм — неэгоизм») |
| 5. болезнь и смерть бе- зобразные |
болезнь и смерть небезоб- разные (незаметные) |
смерть без болезни, пре- красная |
Нетрудно заметить, что ценность изображенных миров также резко различна и возрастает по мере близости персонажа к миру природы (и, соответственно, удаленности от мира цивилизации).
В эту трехступенчатую систему противопоставлений легко вписывается и рассмотренное выше количественное соотношение:
| I | II | III |
| мир, описываемый «мно- гими словами» |
мир, описываемый «мень- шим количеством слов» |
мир, описываемый «ми- нимальным количеством слов» |
Сразу же отметим, что важны для нас не абсолютные цифровые показатели, а их отношение к величине текста в целом и между собой. Полученные при подсчете данные имеют, таким образом, двойную природу. Как компоненты статистической модели (некие величины) они носят вероятностный характер (что, при небольшом объеме рассказа, обусловливает их приближенность, большую возможность ошибки). Но как компоненты семиотической модели (как отношения) они получают и некоторый «абсолютный» смысл: данное художественное значение может быть выражено лишь данной композицией и, в частности, лишь данным соотношением частей10.
Возвратимся, однако, к рассмотрению оппозиции «подробный — краткий». Нетрудно заметить, что это противопоставление носит иной характер, чем приведенные до него. Оппозиции 1—5 касались плана содержания текста (план выражения в них определялся, в конечном счете, общеязыковым значением употребляемых в тексте слов и поэтому автоматизировался) — противопоставление «подробный — краткий» относится к плану выражения, и, казалось бы, только к нему.
При восприятии текста, однако, происходит интересный двусторонний процесс, свидетельствующий об относительности этого различия в художественном произведении.
С одной стороны, указанная особенность композиции достаточно ярко выражена (соотношение 3 : 1 достаточно велико, чтобы быть замеченным «неискушенным читателем»); наряду с членением текста на три части, она оказывается наиболее заметным признаком сверхъязыковой композиции текста. Поэтому оппозиция «подробно изображенный — кратко изображенный», наложенная на оппозиции 1—5, начинает осмысляться как план выражения для противопоставлений «чисто содержательных» («мир личности» ↔ «мир внеличностный», «мир эгоизма» ↔«мир неэгоистический» и т. д. и т. п.). Сами «содержательные» антитезы при этом резко меняют свой характер. Получая в качестве плана выражения определенные, не входящие в естественный язык композиционные структуры, они начинают и в плане содержания восприниматься как не покрываемые полностью общеязыковыми значениями определяющих их слов и словосочетаний (например: «Эгоизм, в данном рассказе, — это не только то, что мы обычно называем этим словом, но и нечто иное, в частности то, что может быть изображено только данным способом — путем подробных, детализованных описаний» и т. д.). Так происходит превращение «чисто содержательных» (то есть с автоматизированным планом выражения) структур: бытовых, философских и других — в художественные, наполненные окказиональным, вне данного текста не существующим содержанием. С другой стороны, однако, происходит семантизация самой оппозиции «подробный — краткий». Под воздействием:
а) презумпции значения всех элементов плана выражения в художественных текстах;
б) презумпции иконичности (в данном случае — «индексальности») художественного знака — наличия неких объяснимых соответствий между элементами содержания и выражения;
в) бытового («аксиоматического») представления о прямом соотношении между длиной сообщения и количеством информации, — возникает представление о том, что миры, при изображении которых для описания одного и того же события (смерти) необходимо создать тексты различной длины, — это миры разной степени сложности. Так «содержательные» оппозиции дополняются еще одной:
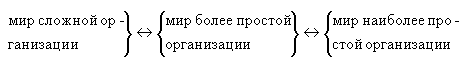
Эту оппозицию следует считать одной из самых основных в тексте: именно она вводит в рассказ центральный для всего молодого Толстого и неоднократно отмечавшийся исследователями оттенок «руссоизма». Тем любопытнее, что столь кардинальное противопоставление возникает не на уровне словесных высказываний или сюжетных коллизий, а в результате семантизации количественных соотношений частей текста.
Выше уже говорилось, что частотные параметры художественного текста могут получать значения лишь в том случае, если их рассматривать как соотношения величин. Никакого иного (даже самого общего, типа «много» ↔ «мало») значения эти данные не имеют и иметь не могут. Поэтому чем более однотипных (подлежащих сравнению) количественных данных имеется в нашем распоряжении, тем менее тривиальные результаты мы можем получить из их сопоставления.
Сравним композицию «Трех смертей» и рассказ А. П. Чехова «Ионыч». Основания для сравнения:
1. Оба рассказа состоят из четко семантически противопоставленных трех частей.
2. Части эти количественно не равны, причем и в «Ионыче», как и в «Трех смертях», располагаются в порядке убывания размеров.
Количественное неравенство трех частей (первая часть — «молодой Ионыч» — гл. I–III; вторая часть — «Прошло четыре года…» — гл. IV; третья часть — «Прошло еще несколько лет…» — гл. V) так же, как и в «Трех смертях», выражено достаточно отчетливо — 3317 : 1609 : 449 (словоупотреблений), то есть 8 : 4 : 1 (с точностью до 0,1–7,2 : 3,6: I)11. Возникают уже описанные условия для семантизации отношения «подробно изображенный — кратко изображенный». Отношение это также накладывается на «содержательные» оппозиции:
I молодой Ионыч |
II Ионыч «через четырегода |
III Ионыч «еще через не-сколько лет» |
| 1. потребность контактов с людьми |
уменьшение потребности контактов |
исчезновение потребнос- ти контактов, враждеб- ность к людям |
| 2. сила эмоций (любовь, чувство природы) |
ослабление эмоций (лю- бовь — лишь «огонек») |
полное притупление эмоций |
| 3. работа мысли, наличие «интересов» |
притупление мысли, суже- ние интересов |
полное умственное отуп- ление, отсутствие интере- са к миру |
| 4. молодость как при- частность к миру кра- соты |
«пополнел», «раздобрел» | «еще больше пополнел, ожирел», «не человек, а языческий бог» (внешнее безобразие) |
| 5. не богат, интерес к деньгам почти не выражен |
богат; растет любовь к деньгам |
очень богат; интерес к деньгам и вещам — ос- новное содержание жизни |
Внешне приведенная система оппозиций не очень сильно напоминает «Три смерти» и, как кажется, дает мало оснований и для сближения, и для противопоставления текстов. Однако явное сходство плана выражения — важный сигнал для поисков сходства плана содержания. И действительно, если мы обратим внимание не только на сопоставляемые признаки, но и на то, как они сопоставляются, то обнаружим многое, делающее вполне оправданным сравнение текстов.
Это, с одной стороны, сходства:
1. Тождественная логическая природа оппозиций: в «Ионыче», как и в «Трех смертях», они строятся по градуальному принципу, с нулевым признаком качества в одной из трех групп (немаркированный член оппозиции) и противопоставлением большей / меньшей интенсивности этого же признака в двух других группах (маркированные члены оппозиции).
2. В обоих произведениях в большинстве противопоставлений немаркированный член оппозиции характеризует мир третьей (самой короткой, заключительной) части текста; однако в обоих имеется и минимум одно противопоставление (в приведенных таблицах — оппозиция 5), где неотмеченность, отсутствие признака — свойства мира первой части текста, а максимальная выраженность признака характеризует третью часть (для Толстого это критерий красоты, для Чехова — причастность к материальным благам).
3. Наложив «содержательные» антитезы на оппозицию «развернутое / краткое изображение мира», мы получаем, как и в «Трех смертях», проти вопоставление: «сложность — простота изображаемого». Художественный текст в обоих случаях движется от показа сложной, многосторонней (= требующей детального раскрытия) жизни к показу жизни более простой, примитивной, для обрисовки которой достаточен «минимум слов».
4. Наконец, необходимо отметить, что, на каких-то достаточно абстрактных уровнях, содержание противопоставляемых признаков в рассказах Толстого и Чехова также оказывается в известной мере близким. Так, сквозь все три части обоих произведений проходят критерий интеллектуальности (яркости / блеклости, истинности / ложности человеческого сознания), этические критерии (отношение персонажей к их окружению), критерий эмоциональности и, наконец, эстетическая «мерка» — отношение персонажа к миру красоты (для обоих текстов связанному с природой).
Итак, оба текста, сближенные на основе сходства чисто количественных признаков, оказались родственными и по содержанию. Вместе с тем наложение оппозиции «пространный — краткий» на остальные антитезы рассказа Чехова позволяет обнаружить и весьма существенные не различия даже, а принципиальные расхождения в художественном видении мира у обоих писателей.
У Толстого в качестве самого ценного выступает самый простой из трех миров рассказа (изображенный наиболее лаконично). Уменьшение интенсивности тех или иных признаков, вплоть до полного их исчезновения, — это уменьшение и исчезновение всего ненужного, излишнего: эгоизма, рассудка (лишь мешающего постижению великих истин), разделяющего людей личностного начала и т. д. и т. п. Исчезают признаки, негативная оценка которых самоочевидна для автора и настойчиво внушается читателю. При этом сам процесс «освобождения от признаков» изображается как восхождение к нравственной норме, а их отсутствие — как признак нормального бытия12. При этом, в силу рассмотренного выше двустороннего соотношения планов содержания и выражения, сам принцип краткого описания становится адекватным описанию прекрасного, гармонического мира и — более того — синонимом гармонической структуры описания.
У Чехова повествование строится иначе и прямо противоположно. Наиболее ценный мир — это мир наиболее сложный (и изображенный наиболее развернуто). По мере превращения молодого, тянувшегося к поэзии земского врача в разжиревшего мещанина13 происходит утрата лучших человеческих качеств: способности к контактам, глубины эмоций, широты интеллектуальных интересов. В противоположность рассказу Толстого, исчезают признаки, наполненные позитивным содержанием. Но одновременно, опять же в противоположность «Трем смертям», в качестве нормы выступает полное, наполненное «всем человеческим», ярко выраженное и сложно-противоречивое бытие, а процесс «освобождения от признаков» становится синонимом страшной пустоты. Не случайно у Толстого по мере приближения к «миру, освобожденному от признаков», единственно возрастающим качеством оказывается красота, а у Чехова — богатство, деньги, вещи. Там, где Толстой видит идеал простой и естественной жизни, — Чехов видит пустоту. Соответствующим образом противоположно Толстому оценивается и семантизированный критерий «быть подробно / кратко изложенным».
Так тема «Чехов и Толстой» превращается в важнейшую и еще недостаточно изученную тему чеховского противостояния патриархальным идеям Толстого, причем «полемика» из уровня прямых высказываний переносится на уровень собственно художественных построений.
Как видим, количественные соотношения в художественном тексте, как и все вообще знаки в произведениях искусства, оказываются не только связанными с семантикой, но и неизбежно включенными в процесс окказионального смыслообразования и, в свою очередь, наполненными окказиональной семантикой.
В качестве примера можно было бы привести и гораздо чаще встречающиеся феномены: соотношение «подробно / кратко изображенный» применительно к делению персонажей на главных и «второстепенных», описание с разной степенью детализованности («различным количеством слов») явлений, интуитивно воспринимаемых как явления одинаковой сложности, и с равной степенью детализованности — явлений различной сложности («смена планов») и т. д. и т. п. Всюду здесь мы можем поставить вопрос о функциональной значимости количественных соотношений частей текста.
Можно возразить, что во всех этих случаях количественные соотношения соответствуют каким-то реально данным членениям текста (частям, главам и т. д.), в то время как частотные различия, выявляемые частотным словарем, не связаны с таким членением и, следовательно, могут оказаться критерием, навязанным тексту извне, не имеющим соответствий в плане содержания произведения. Однако, во-первых, определение частотности слова из суммы его словоупотреблений ничем не отличается от выделения любого элемента при парадигматическом подходе к тексту (например, от механизма обнаружения персонажей, пейзажей, диалогов и т. д.). «Частые» и «редкие» слова противопоставлены не менее «реально», чем, к примеру, «главные» и второстепенные персонажи. Во-вторых, как и все сквозные (а не локальные) упорядоченности текста, они обнаруживают свое значение не столько при внутритекстовом анализе, сколько при типологическом сопоставлении текстов. Разумеется, и при анализе одного текста можно поставить вопрос о значении именно данного соотношения данных «частых» и «редких» слов. Думается, однако, что наименее тривиальные результаты можно получить при сопоставлении различных частотных словарей, а также при соотнесении последних с интуитивными представлениями, с каким-либо нестатистическим описанием и т. д. Можно с уверенностью сказать, что сопоставление (в указанном широком смысле) присутствует в более или менее явном виде в любой попытке статистического описания. Это не удивительно. Ведь, вообще говоря, любые изучаемые факты неизбежно включаются в определенную систему связей, соотносятся с некоторым фоном — в этом, собственно, и состоит их изучение. В развитых науках таким фоном, к которому вольно или невольно апеллируют все вновь получаемые сведения, служат сложившиеся теоретические представления. Благодаря тому, что последние выступают как прочно сложившиеся, фундаментальные категории, сама апелляция к ним может носить неявный, скрытый для самого исследователя характер. Иное положение возникает в новых, не сложившихся областях знаний, где не сформировался определенный подход к изучаемым явлениям, не определились основные параметры, в которых эти явления должны описываться. Добытые данные не с чем соотнести, а значит, невозможно и осмыслить. Статистическое описание языка находится именно в таком положении, и именно в этом, очевидно, заключена главная причина тех трудностей, которые возникают при интерпретации имеющихся данных.
В этом случае особенно возрастает роль сопоставления добываемых фактов друг с другом; в этих сопоставлениях и должна, в конечном счете, сложиться система тождеств и различий, образующая любую теорию и служащая фундаментом исследования. Поэтому на данном этапе сопоставление по необходимости должно носить обязательно эксплицитный характер: оно не является само собой разумеющимся, исследователю приходится самому активно искать для него пути и средства.
К этому общему рассуждению необходимо добавить, что при исследовании поэтического языка значение сопоставлений еще более возрастает, поскольку всякий поэтический стиль конституируется в этом своем качестве лишь в противопоставлении с нормами, прежде всего, «бытового» языка, а также других поэтических (и, шире, вообще литературных) стилей. Именно поэтому здесь значимость того или иного слова раскрывается не столько в абсолютной частоте употребления, сколько в его сравнительной употребительности относительно других текстов.
Поэтому едва ли в частотном списке могут быть непосредственно выделены некоторые частотные зоны, соответствующие определенным классам лексики. Правда, известно, что служебные слова, местоимения, модальные глаголы располагаются в верхней части любого частотного списка, к какому бы стилю он ни относился. Однако даже эта закономерность допускает исключения; слова тех же разрядов встречаются и в низкочастотных зонах14, так что на основании данного признака мы не могли бы, например, формализовать принадлежность слова к «неполнозначному» классу (к служебным или местоименным словам). Еще сложнее обстоит дело с классами слов, характеризующих какой-либо стиль, жанр (или, напротив, имеющих нейтральный характер). По-видимому, слова, принадлежащие к каждому из подобных разрядов, располагаются на всем протяжении списка, так что, зная частоту слова, мы ничего еще не можем сказать о его стилистической принадлежности. В самом деле, если некоторое слово оказалось высокочастотным, то это может значить:
а) что это «нейтральное» слово, широко употребительное в различных стилях;
б) что его частота резко «завышена» в данном стиле и поэтому слово может считаться характерным для последнего;
в) что его частота занижена в данном стиле, так как в других стилях оно имеет еще большую частоту15.
В свою очередь, если слово в списке оказалось низкочастотным, это может означать:
а) что данное слово вообще малоупотребительно в языке;
б) что слово избегается в данном стиле, в отличие от других стилей;
в) что частота слова завышена в данном стиле, так как в других стилях оно встречается еще реже.
Приведенные рассуждения показывают, что значимым оказывается не столько частота слова в определенном подъязыке16, сколько распределение его в различных сравниваемых подъязыках. Важно не то, часто или редко встречается то или иное слово, важно, насколько равномерно оно встречается в различных группах текстов. Именно это характеризует как само слово, так и те тексты, в которых оно употребляется преимущественно или, напротив, избегается.
Ниже мы попытаемся наметить некоторые возможные приемы сопоставительного анализа данных частотного словаря. Однако предварительно необходимо заметить, что для того, чтобы подобный анализ поэтических словарей в будущем оказался возможен, данные словари должны расширить содержащуюся в них информацию. Прежде всего, всякий словарь должен сопровождаться указанием на объем выборки, из которой он извлечен (в количестве словоупотреблений). Не располагая такого рода информацией, невозможно сколько-нибудь строго сравнивать частотные списки, возможным окажется лишь весьма приблизительное сравнение ранжирования слов17.
Известно, далее, что в настоящее время складывается практика построения поэтических словарей как списков слов-лексем (а не словоформ, как в большинстве случаев, хотя и не всегда, строят словари лингвистические). Такой подход представляется вполне разумным, так как в интересующем нас случае именно распределение словарных единиц, а не грамматических форм, очевидно, имеет первостепенное значение. Однако известно, что если в словаре словоформ частота слов и их порядковый номер в списке находятся в полной зависимости (закон Ципфа), то для словаря лексем данная зависимость уже не действует. Следовательно, в этом случае распределение словарных единиц по частотам и по рангам18 обладает известной автономностью, в силу чего исследование этих параметров может дать не вполне адекватные (а следовательно, взаимодополняющие) результаты. Поэтому важным параметром частотного поэтического словаря, по нашему мнению, должен стать ранг слова.
Рассмотрим теперь, с учетом сделанных замечаний, некоторые приемы анализа частотных списков.
Как известно, наиболее часто применяемым в настоящее время способом сопоставления частотных списков является вычисление коэффициента ранговой корреляции19. Данный метод позволяет надежно определить степень близости сравниваемых списков, а следовательно, определить место каждого подъязыка в ряду других, с которыми он сопоставляется. Однако данный метод страдает известной односторонностью: он дает исследуемым подъязыкам лишь характеристику «извне», в их взаимных противопоставлениях. Но в то же время расслоение на группы словарного состава каждого подъязыка и исследование внутренних (для данного списка) противопоставлений таких групп оказывается невозможным. В этом отношении более универсальным и более отвечающим поставленным в настоящей работе задачам представляется другой критерий сравнения — так называемый коэффициент стабильности20.
Коэффициент стабильности слова (∆) показывает, насколько равномерно представлено данное слово в исследуемых списках. Он вычисляется по формуле:
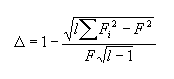 | (1) |
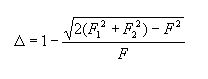 | (2) |
Однако формулы (1) и (2) пригодны только для сравнения словарей равного объема. При неравном объеме (что является как раз обычной ситуацией для поэтических словарей) формула усложняется следующим образом:
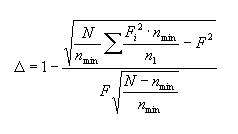 | (3) |
где ni — объем выборки, на основании которой составлен тот список, где данное слово имеет частоту Fi; nmin — объем наименьшей из рассматриваемых выборок; N — суммарный объем всех выборок. Для случая l=2 формула (3) преобразуется:
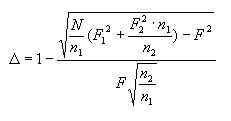 | (4) |
где ni — меньшая выборка (ni = nmin).
Выражение ![]() в формуле (1) (и соответствующие ему в других формулах) показывает степень неравномерности встречаемости некоторого слова в различных списках. Его величина колеблется в пределах от 0 (максимальная равномерность) до 1 (максимально возможная неравномерность)21. Обратной величиной является коэффициент стабильности А, который изменяется соответственно от 1 до 0.
в формуле (1) (и соответствующие ему в других формулах) показывает степень неравномерности встречаемости некоторого слова в различных списках. Его величина колеблется в пределах от 0 (максимальная равномерность) до 1 (максимально возможная неравномерность)21. Обратной величиной является коэффициент стабильности А, который изменяется соответственно от 1 до 0.
Для иллюстрации возможностей и способа применения данного критерия сравним распределение ряда слов в поэтическом языке Ал. Блока22 и нормативном русском языке (манифестацией которого будем считать словарь Э. А. Штейнфельдт — Шт.)23. Материал для сравнения может быть взят любой — пусть это будет, например, 50 самых частотных существительных из АБ. Расположив данные слова по убывающему значению ∆24, получим следующий список.
| Слово | F1 (АБ) |
F2 (Шт.) |
∆ | Слово | F1 (АБ) |
F2 (Шт.) |
∆ |
| рука | 70 | 746 | 0,99 | счастье | 71 | 69 | 0,54 |
| глаз | 59 | 458 | 0,97 | ночь | 207 | 164 | 0,50 |
| друг | 51 | 318 | 0,95 | весна | 81 | 65 | 0,49 |
| слово | 76 | 459 | 0,94 | луч | 53 | 41 | 0,48 |
| дверь | 59 | 320 | 0,93 | огонь | 105 | 75 | 0,46 |
| жизнь | 113 | 603 | 0,93 | дух | 53 | 35 | 0,44 |
| лицо | 50 | 262 | 0,92 | сердце | 186 | 125 | 0,44 |
| дорога | 54 | 234 | 0,89 | тишина | 50 | 31 | 0,42 |
| конец | 51 | 199 | 0,88 | туман | 78 | 40 | 0,41 |
| сила | 63 | 245 | 0,88 | звезда | 77 | 41 | 0,38 |
| окно | 63 | 214 | 0,85 | бог | 88 | 40 | 0,34 |
| день | 253 | 816 | 0,84 | душа | 278 | 108 | 0,31 |
| мир | 48 | 152 | 0,84 | тень | 118 | 29 | 0,22 |
| час | 65 | 210 | 0,84 | лента | 121 | 19 | 0,15 |
| голос | 84 | 226 | 0,80 | печаль | 45 | 7*25 | 0,12 |
| земля | 111 | 290 | 0,80 | роза | 48 | 7* | 0,12 |
| путь | 75 | 194 | 0,79 | сумрак | 51 | 7* | 0,12 |
| солнце | 53 | 116 | 0,76 | тайна | 53 | 7* | 0,11 |
| ветер | 54 | 117 | 0,75 | даль | 57 | 7* | 0,09 |
| утро | 51 | 99 | 0,73 | дума | 56 | 7* | 0,09 |
| песня | 110 | 177 | 0,67 | око | 56 | 7* | 0,07 |
| цветок | 72 | 107 | 0,66 | мрак | 63 | 7* | 0,05 |
| свет | 81 | 95 | 0,59 | заря | 78 | 7* | 0,04 |
| небо | 89 | 91 | 0,56 | страсть | 75 | 7* | 0,03 |
| слеза | 47 | 49 | 0,56 | любовь | 101 | 7* | 0,03 |
Уже при первом взгляде на предложенный список можно сделать некоторые заключения. Во-первых, в верхней части списка расположены слова, встречаемость которых у Блока мало отличается от встречаемости в других текстах на русском языке26. Очевидно, данные слова можно рассматривать как немаркированные специально в поэтическом языке Блока. Напротив, в нижней части списка находятся слова, употребительность которых у Блока резко специфична по отношению к языковой норме и которые, следовательно, могут рассматриваться как маркированные. Примечательно, что и в первом, и во втором случае мы встречаемся со словами, имеющими самые различные показатели абсолютной частоты. Это позволяет нам зафиксировать характерные для данного стиля слова как среди высокочастотных, так и среди низкочастотных единиц27.
Нетрудно убедиться, что получаемое распределение слов в основном согласуется с интуитивной оценкой тех или иных словарных единиц как маркированных и немаркированных для языка Блока. Однако на данном этапе анализа еще нельзя говорить о формализации данного интуитивного расчленения, поскольку определенной границы между выделяемыми классами список не дает.
Простейшим приемом формального разбиения является нахождение средней величины (∆) для всего списка как границы между немаркированной — маркированной зоной. В этом случае слова, имеющие ![]() будут оцениваться как «нехарактерные», слова с
будут оцениваться как «нехарактерные», слова с ![]() как характерные для данного языка. В частности, для предложенного списка
как характерные для данного языка. В частности, для предложенного списка ![]() = 0,54, и здесь, очевидно, можно провести границу между верхней и нижней частью списка.
= 0,54, и здесь, очевидно, можно провести границу между верхней и нижней частью списка.
Однако очевидно, что такая процедура позволяет выделить классы лексики лишь в первом приближении. Трудно ожидать, что граница между классами слов носит совершенно однозначный характер и не имеет переходной области, куда входили бы слова с различной, но не вполне отчетливо выраженной характеристикой. В самом деле, распределение разных слов даже в пределах одной группы довольно сильно разнится, и это заставляет предполагать, что выделенные группы не вполне однородны по составу.
Поэтому необходимо выделить «промежуточную зону», в пределах которой располагаются слова со «средним» распределением, а следовательно, без четкой принадлежности к какому-либо из двух выделенных нами классов, и тем самым более четко обозначить сами эти классы. Данная задача также может быть решена формально, путем анализа имеющегося списка. Действительно, все частоты в словаре не носят абсолютного характера, а должны рассматриваться с учетом возможной относительной ошибки. То же, разумеется, можно сказать и об их показателе стабильности, поскольку он непосредственно зависит от соотношения частот. При этом, очевидно,. есть слова, для которых такое варьирование величины Д оказывается несущественным, поскольку в любом случае они не покидают той группы, к которой относятся. Например, в нашем списке слово лицо зафиксировано с частотами 50 и 262. Однако, с учетом относительной ошибки, истинная величина этих частот колеблется в пределах 37 ≤ F1 ≤ 68 и 200 ≤ F2 ≤ 292. Рассмотрим крайние случаи, когда величины F1 и F2 максимально и минимально различаются:
а) F1 = 37, F2 = 292
б) F1 = 63, F2 = 230
Тогда ∆а = 0,98; ∆б = 0,87. Однако эти колебания для нас несущественны, так как при всех условиях ∆ > 0,54, то есть слово лицо остается в пределах группы «нейтральных» слов.
С другой стороны, величина ∆ у слова весна колеблется в пределах 0,37 ≤ ∆ ≤ 0,61, то есть в принципе данное слово могло бы оказаться как в верхней, так и в нижней половине таблицы. Следовательно, то обстоятельство, что в данном случае его распределение оказалось превышающим среднюю границу, еще не дает нам основания квалифицировать его как «нейтральное» слово.
Таким образом, к маргинальным классам слов могут быть отнесены только такие единицы, распределение которых остается выше или ниже установленного порога при любом соотношении частот, возможном при учете относительной ошибки. Слова, не удовлетворяющие данному условию, должны быть отнесены в промежуточную группу.
С учетом данной поправки, наш список будет разбит на три части. Верхнюю часть составят первые 22 слова (∆ ≥ 0,66), нижнюю — 17 слов (∆ ≥ 0,41), 11 слов (0,42 ≤ ∆ ≤ 0,59) составляют промежуточную группу.
Таким образом, сравнительный анализ на основе критерия ∆ позволяет формально выделить группы слов, являющихся стилистически нейтральными и характерными для некоторого стиля (или подъязыка). Это позволяет подвергнуть лексический состав исследуемого стиля дальнейшему анализу. Во-первых, обнаруживаются те смысловые группы, которые оказываются характерными (или, напротив, нехарактерными) для данного стиля. Так, даже в нашем очень небольшом примере обращают на себя внимание с этой точки зрения такие группы слов, как, с одной стороны, рука, глаз, голос, лицо или мир, земля, солнце, ветер (нейтральные) и, с другой стороны, тень, мрак, сумрак (ср. также печаль, тайна) или любовь — страсть; дух — сердце — душа. Конечно, увеличение исследуемого материала должно дать более полную картину. Важно лишь отметить, что мы получаем возможность группировать слова в семантические поля, уже располагая формально полученным определением значимости тех или иных слов для исследуемого поэтического языка.
Но и сами семантические поля могут быть получены формально. Дело в том, что, как показывают наблюдения над сравнением различных списков, слова, принадлежащие к одному семантическому полю, нередко весьма разнятся с точки зрения абсолютной употребительности, но оказываются весьма близкими по характеру распределения в различных текстах. Это положение подтверждают и приведенные выше примеры: во всех указанных нами группах различие величины ∆ у разных слов не превышало 0,20, то есть весьма незначительной величины (учитывая возможные колебания ∆ под влиянием относительной ошибки в определении частоты). Встречаются, однако, и другие случаи, когда слова, однородные по смыслу и принадлежащие как будто бы к одному семантическому полю, резко разнятся с точки зрения своего распределения. Таковы в нашем списке противопоставления: утро, день — ночь; свет — мрак; земля — небо; солнце — звезда; рука, глаз, лицо — сердце; цветок — роза. Значительное различие в распределении слов, которые с точки зрения общеязыковых норм представляются семантически однородными, может быть объяснено тем, что в исследуемом поэтическом языке их семантические отношения смещены по сравнению с общеязыковыми, как-то переосмыслены и несут некоторую специфическую для данного случая функцию. Так, вслед за составлением списков нейтральных и маркированных слов, нейтральных и маркированных семантических полей оказывается возможным выделить нейтральные и маркированные смысловые противопоставления. При этом мы можем также определить, какой из членов маркированных противопоставлений является сильным, то есть является положительным носителем дополнительной смысловой нагрузки. Таковым, конечно, будет слово из «маркированного» разряда (то есть с малым ∆), тогда как «нейтральное» слово будет слабым членом оппозиции, получающим дополнительное осмысление лишь в сопоставлении, в противопоставлении с сильным. В наших примерах сильными являются слова ночь, мрак, небо, звезда, сердце, роза, в противоположность словам день (утрр), свет, земля, солнце и т. д. Как видим, составление списков семантических оппозиций и выяснение, какие из членов данных оппозиций являются сильными, также может способствовать описанию семантической структуры поэтического языка — описанию, носящему формальный характер.
Таковы некоторые результаты, которые могут быть получены при исследовании на базе статистических характеристик семантической структуры поэтического языка в соотнесении с соответствующей общеязыковой структурой. Другой путь, который открывают предлагаемые исследовательские приемы, состоит в сравнении между собой различных поэтических языков (или различных жанров в творчестве одного автора). В этом случае речь будет идти уже не о характеристике поэтического языка как вторичной моделирующей системы, преобразующей определенным образом структуру (в данном случае — смысловую) естественного языка (которая служит здесь материалом), а об исследовании противопоставления различных поэтических систем.
В этом случае открывается возможность представить различные поэтические языки в виде системы, каждый член которой конституируется определенными противопоставлениями с другими. Характер такого противопоставления (определяемый количественно — мощностью маркированных классов, то есть, в конечном счете, величиной ∆, а качественно — набором маркированных семантических гнезд и семантических оппозиций) может служить показателем относительной близости или удаленности друг от друга соответствующих поэтических языков. С другой стороны, семантическая структура каждого такого языка в отдельности получит более дифференцированную характеристику (уже с точки зрения многих противопоставлений, а не только одного — с естественным языком) и может быть интерпретирована как преобразование не только общеязыковых, но и некоторых стилистических (жанровых) норм.
Мы можем, следовательно, сделать вывод, что статистическая характеристика текстов является формальным показателем, способным (наряду с другими формальными показателями) привести к построению модели языковой структуры, манифестируемой в данных текстах. Дальнейшие исследования должны показать, насколько существенным окажется присоединение данного критерия к другим известным критериям структурного описания языка.
ПРИМЕЧАНИЯ
1 Москович В. А. Статистка и семантика. М., 1969; Шайкевич А. Я. Распределение слов в тексте и выделение семантических полей // Иностранные языки в высшей школе. 2. М., 1963.
2 См., например: Алексеев П. М. Частотные словари и приемы их составления // Статистика речи. Л., 1968.
3 Нам могут возразить, что все частоты в поэтическом словаре определяются точно, так как здесь возможно исчерпывающее обозрение всех текстов данного автора, в отличие от лингвистического словаря, который оперирует лишь с наугад взятой выборкой. Однако если мы исходим из противопоставления поэтического языка как структуры, обеспечивающей порождение данных поэтических текстов и их декодирование, и поэтической речи как манифестации данного языка, мы должны признать, что наша ситуация в принципе не отличается от лингвистической: реально созданные тексты являются лишь «выборкой» из бесконечного множества текстов, которые могли бы быть порождены исследуемым языком. В подтверждение данного тезиса достаточно привести такое простое рассуждение: можем ли мы считать, что если во всех текстах данного автора ни разу не встретилось некоторое слово, то этого слова не было в его языке?
4 Штейнфельдт Э. А. Частотный словарь современного русского литературного языка. Таллин, 1963.
5 Фрумкина Р. М., Василевич А. П. Вероятность слова и восприятие речи // Вопросы порождения речи и обучения языку. М., 1967. С. 20.
6 См.: Андрющенко В. М. Некоторые приемы анализа лингвостатистических данных // Иностранные языки в школе. 1966. № 3.
7 Разумеется, с возрастанием объема выборки увеличивается и зона достоверных суждений при заданном соотношении частот.
8 Если соблюдать точные соотношения словоупотреблений по главам (I, III — II — IV), то цифры будут несколько иными: 2361 — 849 — 459. Если руководствоваться содержанием, то точнее было бы, однако, начало IV главы связать с темой второй смерти (соответственно получим: 2361 — 1029 — 279). Цифры, приведенные в основном тексте, вообще не включают первый кусок IV главы (180 словоупотреблений); думается, что этот отрезок текста функционально выполняет роль сюжетной связки, соединяющей вторую и третью тему рассказа. Существенно, однако, что при любом способе подсчета соотношение частей остается в принципе сходным.
9 Характер этих оппозиций сложен. Как правило, характеристики I–II строятся по принципу градуального уменьшения (2, 3, 4) или возрастания (5) степени качества. В III (для 2, 3, 4) соответствующий признак качеств становится нулевым, так что мы можем считать III немаркированным членом оппозиции, противопоставленным I и II как маркированным. Для признака 5 можно рассматриватьI как немаркированный член оппозиции, аII иIII как маркированные с возрастающей степенью качества. Различие в характерах оппозиций2, 3, 4, с одной стороны, и 5, с другой, весьма существенно (см. с. 687 бумажного издания).
10 Представленные выше рассуждения свидетельствуют о том, что в тексте семантизируются лишь количественные соотношения «много (словоупотреблений)» — «меньше» — «мало». Большая степень неопределенности этого соотношения во многом сближает структурную и статистическую модель текста. Однако весьма вероятно предположить, что семиотический анализ других (особенно низших) уровней текста обнаружит качественную природу («значение») и более точных числовых соотношений. В частности, возможно, что отношение частей (9 : 3 : 1) также имеет не вероятностный, а структурный характер, отражая установку на симметричность «трехчастной» композиции рассказа. В этом случае функционально значимой окажется даже приближенность, неполнота этого соотношения, наличие «ошибки» (более точно — 8,4 : 3 : 1). Подобную неполноту симметрии можно было бы сопоставить с важнейшей для художественной системы тенденцией к неполной симметрии (неполной предсказуемости) текста.
11 И здесь, как и в «Трех смертях», в соотношении частей можно видеть и тяготение к симметрии (хотя не столь четко выдержанное), и тенденцию к ее разрушению (вернее, к неполной ее реализации).
12 Нарушается эта закономерность лишь в противопоставлении безобразного / прекрасного, которое строится по принципу градуального возрастания признака — и признака положительного.
Различие между эстетическим критерием оценки, с одной стороны, и этико-интеллектуалистическими характеристиками, с другой, весьма примечательно. Здесь мы сталкиваемся с одним из важнейших диалектических противоречий творчества Толстого. Утверждение максимальной ценности «мира отсутствующих признаков» (мир внеличностный, вне сознания, без суеты и т. д.) подготавливает «буддистские» мотивы позднего Толстого (вплоть до представления о том, что лучший текст — это отказ от слов — «текст с нулевым количеством слов» — молчание). Вместе с тем очень существенно, что как раз самый ценный из миров — природный — оказывается носителем максимально выраженного позитивного признака красоты. Последняя особенность присуща не только молодому Толстому (ср. во многом противоположный «Трем смертям» по содержанию и композиции рассказ «Два гусара», где критерий ценности персонажа совпадает с наличием и яркой выраженностью в нем «всего человеческого»). Это же отношение к «выраженным» ценностям (активное добро, красота, сила) как к подлинным пробивается и сквозь «буддизм» и отречение позднего Толстого (ср., например, критерий оценки героя в «Живом трупе» и «Хаджи Мурате»).
13 Из нашего разбора исключена тема «Старцев и Туркины», как не связанная с задачей этого разбора.
14 Например, в словаре Э. А. Штейнфельдт предлог благодаря имеет частоту 17.
15 Все эти случаи представлены, например, среди 100 самых частотных существительных в списке, полученном одним из авторов настоящей работы на основе обследования немецких технических текстов. Здесь встретились и общеупотребительные слова — Ende, Frage, и специальные — Messer, Pumpe, Pflug, и такие, которые, будучи достаточно употребительны в данных текстах, все же значительно чаще встречаются в не-котррых других стилях (Form, Jahre).
16 Мы будем называть «подъязыком» структуру, которая манифестируется некоторым подмножеством множества текстов, написанных на данном языке, сформированным по какому-либо признаку (стилистическая, тематическая, жанровая характеристика, авторская принадлежность и т. п.).
17 Впрочем, для словарей, публикуемых полностью (заметим попутно, что именно так, по возможности, должны публиковаться поэтические словари, так как в этом случае, как уже говорилось выше, значимость низкочастотных слов совершенно иная, чем для «бытового» языка), этот пробел отчасти может быть исправлен тем, что объем выборки можно вычислить непосредственно по словарю (суммировав все частоты). Словари же, опубликованные лишь частично, без указания на объем, оказывается возможным использовать для дальнейшего анализа лишь в очень ограниченной степени.
18 Отличие ранга (R) от обычного порядкового номера (i) состоит в том. что один ранговый номер приписывается всем словам, имеющим одинаковую частоту.
19 См.: Фрумкна Р. М. Статистические методы исследования лексики. М., 1964.
20 Данный критерий впервые был предложен в работа: Juilland A., Edwards P. M., Juilland I. Frequency dictionary of rumanian words. The Hague, 1965; Juilland A., Rodrigues E. Ch. Frequency dictionary of Spanish words. The Hague, 1964; см. также: Аyдрющенко В. М. Некоторые вопросы теории и техники составления частотных словарей // Иностранные языки в школе. 1969. № 1. Некоторые свойства данного критерия и возможные пути его применения анализируются в работе: Гаспарова Э. М. Некоторые вопросы корреляции частотных списков // Linguistica. № 2 (Tartu), 1970.
21 В случае, когда слово встречается только в одном из списков и отсутствует во всех других.
22 Манифестацией последнего для нас здесь будет служить публикуемый ниже словарь первого тома лирики Ал. Блока (АБ).
23 Надо, впрочем, заметить, что существенные недостатки в отборе текстов, составляющих базу данного словаря, позволяют считать его репрезентатором статистических параметров русского языка лишь условно. При наличии более репрезентативного словаря, опирающегося на тексты различных стилей, возможности для сравнения могли бы быть шире. Однако даже такой несовершенный объект сопоставления позволяет, как увидим ниже, получить известные результаты.
24 nАБ = 40 тыс. словоупотреблений, nШт. = 400 тыс. словоупотреблений. Поэтому ∆ вычисляется по формуле:
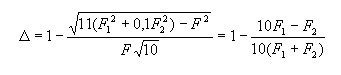
25 В списке Шт. слова доведены до частоты 14. Поэтому словам, не встреченным в списке Шт., мы приписываем условную частоту F* = 7 (из расчета, что значение F в этом случае неопределенно в пределах 0 ≤ F ≤ 14).
26 Здесь, правда, необходимо сделать одну оговорку. Поскольку частотные списки не фиксируют явление полисемии, ориентируясь лишь на словоупотребления, мы оказываемся лишены возможности сравнивать употребительность отдельных значений. В силу этого такие слова, как «небо» или «дух», оказываются в верхней части нашего списка, хотя интуитивно очевидно, что в текстах АБ они употребляются преимущественно в ином значении, чем в текстах, на которых базируется Шт.
27 В нашем примере мы ориентировались на частотные слова АБ. Поэтому во всех случаях низкого значения ∆ речь идет о преобладании этих слов у АБ по сравнению со Шт. Однако в принципе «избегаемые» АБ слова также должны были бы дать плохое распределение (малая величина ∆), то есть также оказались бы маркированными (так сказать, отрицательно маркированными) для данного стиля.
* Минц З. Г. Блок и русский символизм: Избранные труды: В 3 кн. СПб.: Искусство – СПб, 2004. Кн. 1: Поэтика Алекстандра Блока. С. 679–698.
Ruthenia, 2006